Essay · June 2026
The Day Hollywood Started Training Robots
How a Technology Stack Built for Movies Became the Foundation of Embodied AI
4604 words · Estimated read time: ~21 mins
In 2009, James Cameron spent an estimated $237 million making Avatar.
Most people remember the blue aliens. Few remember what happened behind the scenes.
Behind every scene was a motion-capture stage covered with infrared cameras. Actors wore suits embedded with reflective markers attached to their shoulders, elbows, wrists, hips, knees, and ankles. Head-mounted rigs recorded subtle facial movements frame by frame. The resulting footage was not stored as video. It was converted into a structured representation of human motion: joint positions, skeletal rotations, facial blendshapes, trajectories through three-dimensional space.
Hollywood built these systems because audiences are surprisingly unforgiving. We immediately notice when a character's weight shifts unnaturally before taking a step. We notice when a smile arrives half a second too late. We notice when a hand reaches for a glass but the fingers close in a way that no human hand ever would.
For decades, the entertainment industry poured billions of dollars into solving this problem. Not how humans think. Not even how humans speak.
It's how humans move.
At the time, all of this effort seemed directed toward a single goal: creating more believable characters.
Looking back, that interpretation feels incomplete. What Hollywood was really building was not a film production pipeline. It was a system for translating human behavior into machine-readable representations.
Movements became coordinates. Expressions became parameters. Physical interactions became structured data. Decades before embodied AI entered the mainstream, the entertainment industry had already spent billions of dollars solving a surprisingly similar problem: how do you teach a machine to understand and reproduce the physical world?
That pipeline turns out to be useful for something far larger than movies. It becomes one of the foundations of embodied AI.
The Migration Path
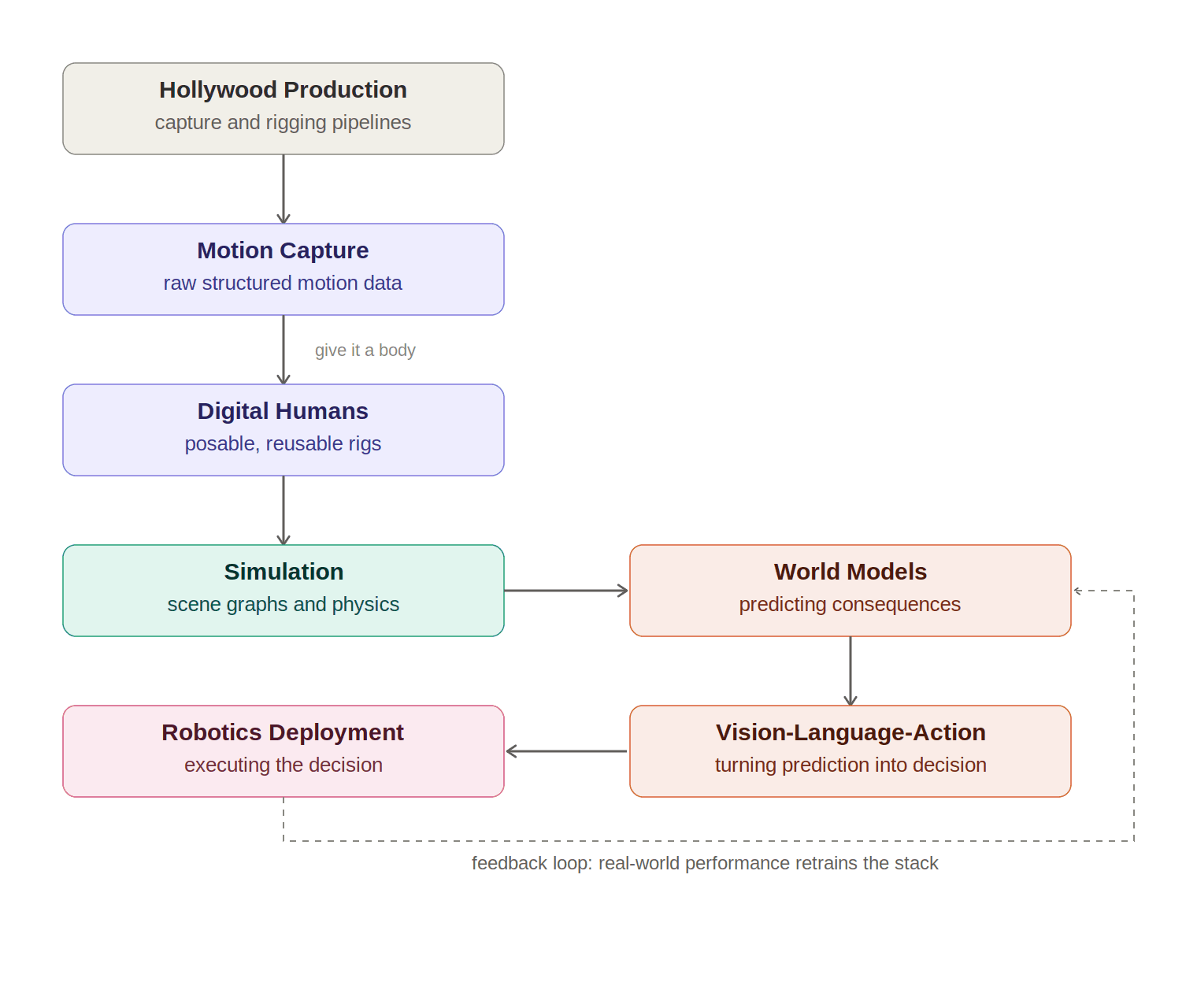
The logic of the stack is easiest to see if you track representations rather than branding. In film and games, a production pipeline starts with capture or authored motion, converts it into character-skeleton and facial-control representations, moves those into interoperable scene files, composes them in larger environments, simulates or previews them, and then renders the result. In robotics, the pipeline starts with demonstrations or teleoperation, converts them into state/action trajectories, places them into scene graphs and simulators, uses predictive models to model future states, trains policies that map observation and language to action, and then evaluates in the real world. The tools differ, but the structure is homologous.
The crucial insight is that the migration does not mean a film mocap clip is directly fed into a humanoid policy. It means the pipeline primitives migrate: synchronized multi-sensor capture, standard scene graphs, skeletal or blendshape abstractions, physics-based preview, neural retargeting, synthetic data generation, and evaluation infrastructure. That is why USD, Isaac Sim, MetaHuman, Audio2Face, GR00T, Helix, and Genie belong in the same map even if they ship into different end markets.
The First Representation Problem
Hollywood's contribution is not “storytelling” in the abstract. It is a very technical answer to a narrow question: how do you convert the messy, continuous motion of a human body into a representation a machine can edit, replay, retarget, and compose? In production, that usually means some combination of body capture, facial capture, witness footage, cleanup, retargeting to a skeleton, and then transfer into a DCC or engine. The output is not text and not sentiment; it is a structured motion record: marker clouds, joint transforms, blendshape weights, camera solves, and synchronized analog signals. C3D's longevity is important precisely because it stores synchronized 3D and analog data in a stable, manufacturer-independent format. USD Skel matters for the same reason at the scene-composition layer: it stores skeleton topology, animation, bindings, joint influences, and blendshape animation in a reusable schema.
That is why the right mental model is not “Hollywood captured emotion.” It is “Hollywood built machine-readable abstractions for human motion.” If a shoulder rotation becomes a joint hierarchy plus time-sampled transforms, and a half-smile becomes named blend shapes plus weight curves, that motion is no longer trapped inside a performance. It becomes a transferable asset. USD explicitly separates skeleton topology, animation, binding, and blendshape animation so that animation and assets can remain modular and instanced. That modularity is exactly what later makes these assets useful in real-time engines and simulation stacks.
A joint hierarchy and a set of blendshape curves are a body, in the sense that they can be posed, animated, and retargeted onto a new character. What they are not, yet, is a product. Turning that raw representation into something a studio, a startup, or eventually a robotics team can actually pick up and use is a separate layer of the stack, and a separate business.
From Pixels to Parameters: Why Digital Humans Matter
The digital-human layer commercialized those abstractions. Epic's MetaHuman moved high-fidelity character creation, animation, and rendering into a broadly accessible product stack; the current MetaHuman site emphasizes creation from scans or presets, animation from single-camera video or even audio, and integration into Unreal. Epic's licensing choice also matters strategically: MetaHuman is included in standard Unreal licensing and is free for users under $1 million in revenue, which dramatically lowers experimentation cost for startups and tool builders.
NVIDIA's Audio2Face sits at a slightly different point in the stack. It is not primarily a character-creator product; it is a speech-to-facial-animation system. Its significance is that it converts audio into machine-generated facial motion and lip sync, and NVIDIA's 2025 decision to open-source it lowers the barrier for developers building more reactive, programmatic digital humans. Once facial animation can be generated from audio streams rather than painstakingly hand-authored, the marginal cost of embodied interfaces falls.
The enterprise-avatar companies show what this looks like when productized. Synthesia's pricing page now presents AI avatars not as novelty media, but as repeatable software economics: $29/month for Starter, $89/month for Creator, enterprise on custom pricing, with 240+ stock avatars at the enterprise tier and a $1,000/year Studio Express avatar add-on. Soul Machines spans from prosumer “build your own AI agent” plans at roughly $12.99/month, $99/month, and $2,700/month, up to Digital Workforce / Workforce Connect products around $40,000/year. That pricing shift matters because it turns digital humans from bespoke VFX artifacts into scalable software categories: training agents, customer-service agents, brand reps, onboarding agents, and interactive sales interfaces.
From an investment standpoint, this layer is already monetizing. The short-term products are not general humanoids. They are AI-powered digital humans, character tooling, facial-animation middleware, synthetic actors, and avatar-based interfaces. Those are the products generating adoption and learning loops now. The subtle but important point is that every such product also accumulates more data about expression, articulation, failure cases, retargeting behavior, and user interaction. That data can later become training infrastructure for richer embodied systems.
A digital human, however well rendered, is still acting inside an empty room. It has a body and a face, but nothing to push against, drop, collide with, or be corrected by. The next layer in the stack exists to give it one.
Simulation as the Control Plane
Simulation is where the entertainment stack stops being a content pipeline and starts becoming AI infrastructure. The key substrate here is scene description. Pixar's OpenUSD was built to make arbitrary 3D scenes interoperable, composable, and non-destructively editable across applications. That sounds like a film-pipeline problem, but it is also exactly a robotics problem: you want robot assets, sensors, environments, materials, lighting, physics, ground truth, and overrides to live inside one coherent scene graph that many tools can read and modify. This is why USD has become such an important bridge technology between Hollywood and VFX on one side and physical AI on the other.
NVIDIA has made the strategic importance of this layer unusually explicit. Isaac Sim is presented as a USD-based, open-source reference framework for robotics simulation, testing, and synthetic data generation. It ingests CAD, URDF, and even real-world captures, converts them to USD, and then supports synthetic-data generation, policy learning, and downstream evaluation. It can export annotations in COCO and KITTI formats, which means it is not just a robotics simulator; it is also a synthetic-data factory for perception stacks.
The deeper strategic point is that simulation is no longer just physics preview. It is now also asset ingestion, data normalization, sensor synthesis, domain randomization, world reconstruction, environment orchestration, and evaluation, all stitched together inside the same USD-based pipeline. Once all of those components are connected, the simulator becomes the highest-leverage place to improve the entire stack.
This is why the most important company in embodied AI may not look like a “robotics company” in the conventional sense. The highest strategic leverage may sit with whoever owns the simulation layer, or more precisely, the pipeline around it. If you own the scene representation, the data-ingestion layer, the synthetic-data engine, the evaluation framework, and the deploy path into training and testing, you can become the toll booth for many downstream products at once.
Economically, this is also where cloud and compute enter the picture in a serious way. Isaac Sim itself is free and open source, but the workload is not. AWS's p5.48xlarge starts around $55.04/hour with 8 H100 GPUs, while Lambda's public pricing shows H100 around $3.99 to $4.29 per GPU hour and B200 around $6.69 to $6.99 per GPU hour depending on configuration. That means simulation-heavy embodied-AI workflows already have visible, industrial-scale unit costs. Once a company is training synthetic-data pipelines or world models at scale, this is not cheap software experimentation. It is capacity planning.
The two big technical risks in this layer remain unchanged. First, rendering realism is not the same thing as physical realism; beautiful worlds can still have bad contact, friction, deformable interactions, or object affordances. Second, simulator convenience can hide evaluation debt: if the simulator makes data generation too easy, teams can overfit to synthetic regularities. The companies that win this layer will therefore need not just better graphics, but better contact models, better sensor realism, stronger evaluation harnesses, and cleaner sim-to-real methodology.
A simulator can stage a world and enforce whatever physics someone coded into it, but staging a world is not the same as understanding one. Knowing what a robot's actions will cause, beyond the narrow set of rules a simulator was given, is a different and harder problem, and it belongs to the next layer.
From Simulation to World Models
“World model” is one of the most overloaded terms in AI right now. The useful definition is not “an AI that makes video.” It is a model that predicts how the state of a world evolves, often under actions or interventions, in a representation useful for understanding, planning, or control. Some world models live in latent space and are optimized for prediction and planning, not photorealism. Others generate interactive worlds directly. Others are domain-specific simulation systems built on top of a broader world-model substrate. Those are materially different things, and treating them as one category causes a lot of confusion.
Meta's V-JEPA 2 is the clearest example of the predictive camp. The paper frames the problem as learning to understand, predict, and plan from observation, combining more than 1 million hours of internet video pretraining with a smaller amount of robot-interaction data. That is important because it uses the internet-scale video prior to get broad physical understanding and the interaction data to connect those representations to action. V-JEPA 2.1 then pushed further on dense, spatially grounded features and reported a 20-point improvement in real-robot grasp success over V-JEPA-2 AC. This family is less about generating pretty worlds and more about learning reusable physical representations.
DeepMind's Genie line sits closer to the interactive-generation camp. Genie started with action-controllable environments from unlabeled videos; Genie 3, as publicly described in 2025, added more persistent and interactive 3D worlds and was framed by DeepMind as a stepping stone toward training agents and robots in virtual environments. The Waymo World Model is the clearest industrialized derivative: it uses a DeepMind/Genie-based stack to generate rare driving edge cases with controllable scene layout, driving action controls, and language controls, including synchronized camera and lidar outputs. That is a direct example of world models becoming operational simulation infrastructure rather than research demos.
NVIDIA Cosmos is trying to occupy a broader, infrastructure-like position. NVIDIA's current Cosmos page describes Cosmos 3 as an “omni-model” with native reasoning, world generation, and action generation, and positions it as a backbone for World Action Models, simulations, and synthetic-video scaling for physical AI. In other words, NVIDIA is explicitly collapsing the boundary between world modeling, synthetic data generation, and downstream policy learning. That is the strongest evidence that the industry is converging on simulation, world-model, and policy as one integrated stack rather than three separate markets.
VLAs matter because they are where the representation finally closes into control. RT-2 established the template in 2023 by taking strong vision-language backbones and expressing robot actions as tokens, so one model could transfer web knowledge into manipulation behavior. Open X-Embodiment and RT-X then made the cross-embodiment data problem more concrete by aggregating data across 22 robots, 21 institutions, and 527 skills. OpenVLA opened the category further in 2024, training on 970k demonstrations and making finetuning more accessible. This is the crucial transition from understanding physical scenes to issuing actions in them.
The architecture is now splitting into two camps. One camp keeps the model relatively unified and emits either discrete action tokens or continuous trajectories. Pi-zero is the best-known recent example of the continuous camp: a VLA flow model for general robot control that uses a pretrained VLM backbone and learns across multiple dexterous embodiments, with continuous actions up to 50 Hz. The other camp separates a slower semantic and perceptual system from a faster visuomotor controller. Figure's Helix and NVIDIA's GR00T N1 both use this dual-system structure because humanoid control imposes stronger latency and dexterity constraints than tabletop manipulation.
The reason this matters for founders is straightforward: the winning action models probably do not look exactly like the winning text models. Robotics has different bottlenecks. Output latency matters more. Safety margins matter more. Contact uncertainty matters more. Action representations matter more. And training data is radically more expensive. That is why so much of the current product motion is around synthetic data, teleop, simulation, dual-system architectures, and better transfer across embodiments. The category is still looking for the architecture that scales as gracefully as language models did.
A model that can decide what to do is still a model, not a robot. Whether any of this survives contact with a real body, real actuators, and a real factory floor is a separate and much less forgiving question.
Robotics and Hardware
The robotics layer is where the stack becomes unforgiving. A good VLA demo is still just a demo unless it survives onboard inference limits, actuator noise, safety constraints, reliability targets, and manufacturing economics. Figure's Helix announcement is important precisely because it is unusually explicit about these constraints: System 2 runs at 7 to 9 Hz for scene understanding and language, System 1 runs at 200 Hz for full upper-body humanoid control, the action space is 35 DoF, and the training set is about 500 hours of high-quality teleoperation with automatically generated language labels. That is a very concrete picture of how much data, architecture split, and control frequency are needed before language to action becomes plausible on a humanoid.
Figure's BotQ announcement is equally important, but for a different reason. It shows that the next bottleneck after policy quality is not just better AI. It is production engineering. BotQ's first-generation line targets 12,000 humanoids per year; Figure emphasizes PLM, ERP, WMS, custom MES, vertical integration around actuators, hands, batteries, and final assembly, and the use of robots in its own manufacturing process. That is what a genuine embodied-AI company starts looking like once it exits the demo stage: part count, tooling, reliability labs, supply chain, in-house test data, and software systems for manufacturing genealogy.
NVIDIA is trying to become the default picks-and-shovels layer for this entire stack. GR00T N1 is an open foundation model for generalist humanoid robots with a dual-system architecture; Isaac Sim and Isaac Lab are the simulator and training substrate; Cosmos is the world-model and synthetic-data layer; the open physical-AI datasets try to reduce data bottlenecks; Newton becomes an open-source GPU-accelerated physics engine built on OpenUSD; and Jetson Thor, Blackwell, and Rubin keep edge and data-center compute on the same roadmap. This is not a collection of adjacent products. It is a deliberate attempt to own the data-to-simulation-to-model-to-deployment loop.
Google is attacking the loop from a different direction. Reuters' March 2025 reporting on Gemini Robotics framed the release as two models: Gemini Robotics, a VLA for physical actions, and Gemini Robotics-ER for embodied reasoning and spatial understanding. The strategic logic here is to bring frontier multimodal reasoning into the robotics stack without necessarily owning the robot hardware itself. That suggests a future market structure in which some companies own hardware, others own world-model and simulation infrastructure, and others own the cognition layer.
Tesla remains strategically relevant mainly because it has the rare combination of factory environments, vertical integration, and a willingness to collect industrial behavior data at scale. Reuters reported in 2024 that Tesla planned internal Optimus use, and subsequent public reporting suggests continued focus on high-volume production lines and internal factory deployment. But the evidence base is still noisier and more promotional than for NVIDIA's developer stack or Figure's engineering posts, so any investment thesis built on Tesla-specific humanoid timelines should be discounted accordingly.
On hardware economics, the story is already concrete enough to matter for company building. AWS p5.48xlarge pricing implies roughly $6.88 per H100 GPU hour at list on-demand pricing, while Lambda's self-serve pricing sits around $3.99 to $4.29 per H100 GPU hour and $6.69 to $6.99 per B200 GPU hour. That is before storage, networking, orchestration, data engineering, or the iteration cost of failed experiments. The immediate implication is that capital efficiency in embodied AI will come less from training a massive model once and more from improving the yield of the whole stack: better demonstrations, better simulation fidelity, better auto-labeling, better policy distillation, better evaluation, and more reusable world models.
None of this came together by accident, and it did not happen because robotics suddenly got easier.
Hollywood's Second Life
This is happening now because several constraints broke at once. First, LLMs and VLMs solved enough of the perception-and-language side to make agent interfaces useful, even before dexterous control is solved. Second, real-time engines and AI animation tools dramatically lowered the cost of creating embodied interfaces and synthetic environments. Third, real-world robot trial-and-error remains too expensive and too slow, which makes simulation and synthetic data economically mandatory rather than optional. Fourth, Hollywood was data-rich but algorithm-poor. AI was algorithm-rich but data-poor.
For most of the past decade, the two evolved in parallel. One side built structured representations of motion, performance, and synthetic worlds. The other built increasingly powerful learners capable of extracting patterns from large-scale data. Only recently have those two stacks started to converge.
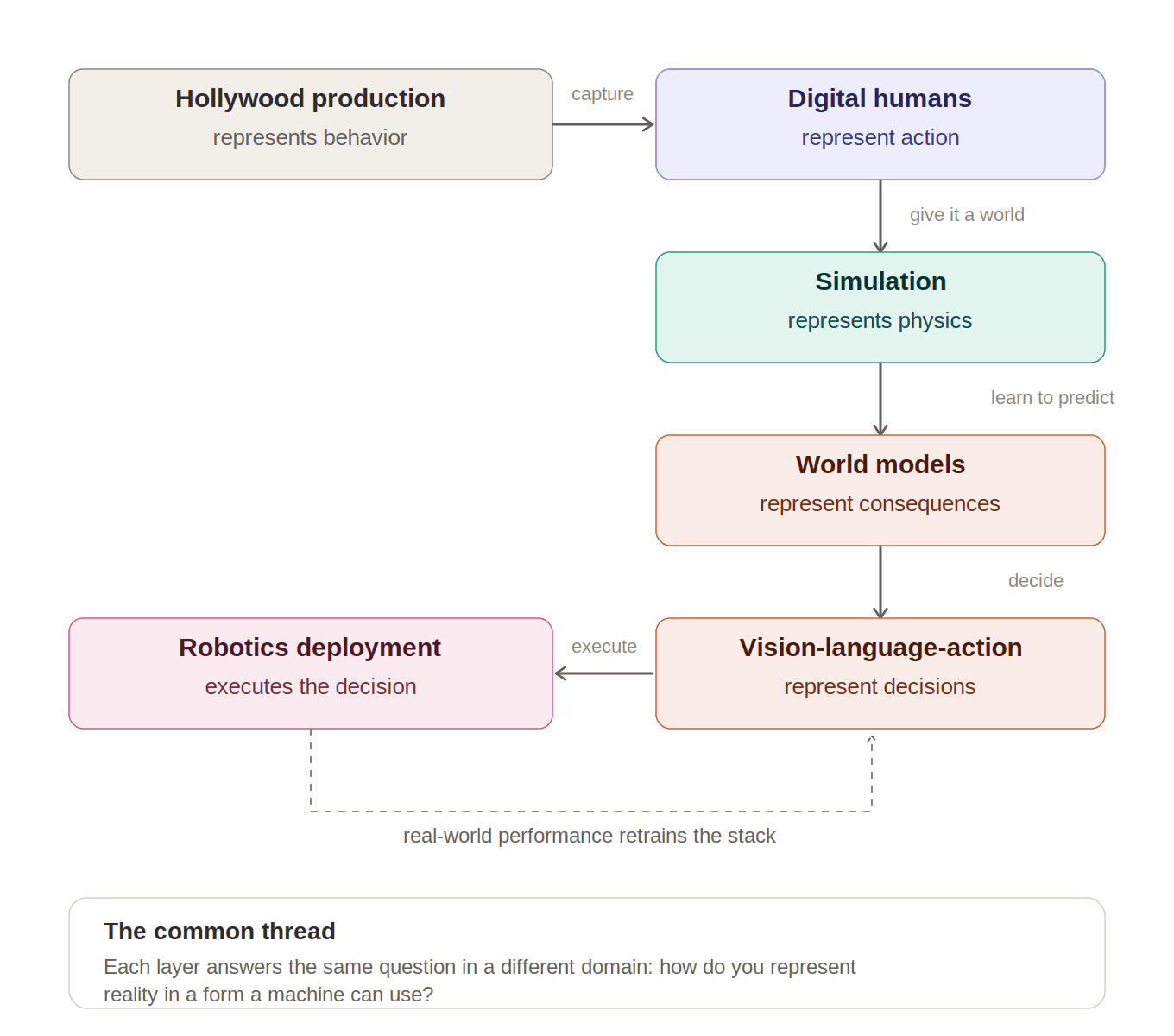
Hollywood did not directly “train robots.” It built the tooling and abstractions for representing human motion and synthetic worlds. Digital-human companies commercialized those abstractions. Simulation platforms turned them into machine-readable environments. World models learned their dynamics. VLA systems translated understanding into action. Robotics is where the loop closes.
Laid end to end, the path looks like this:
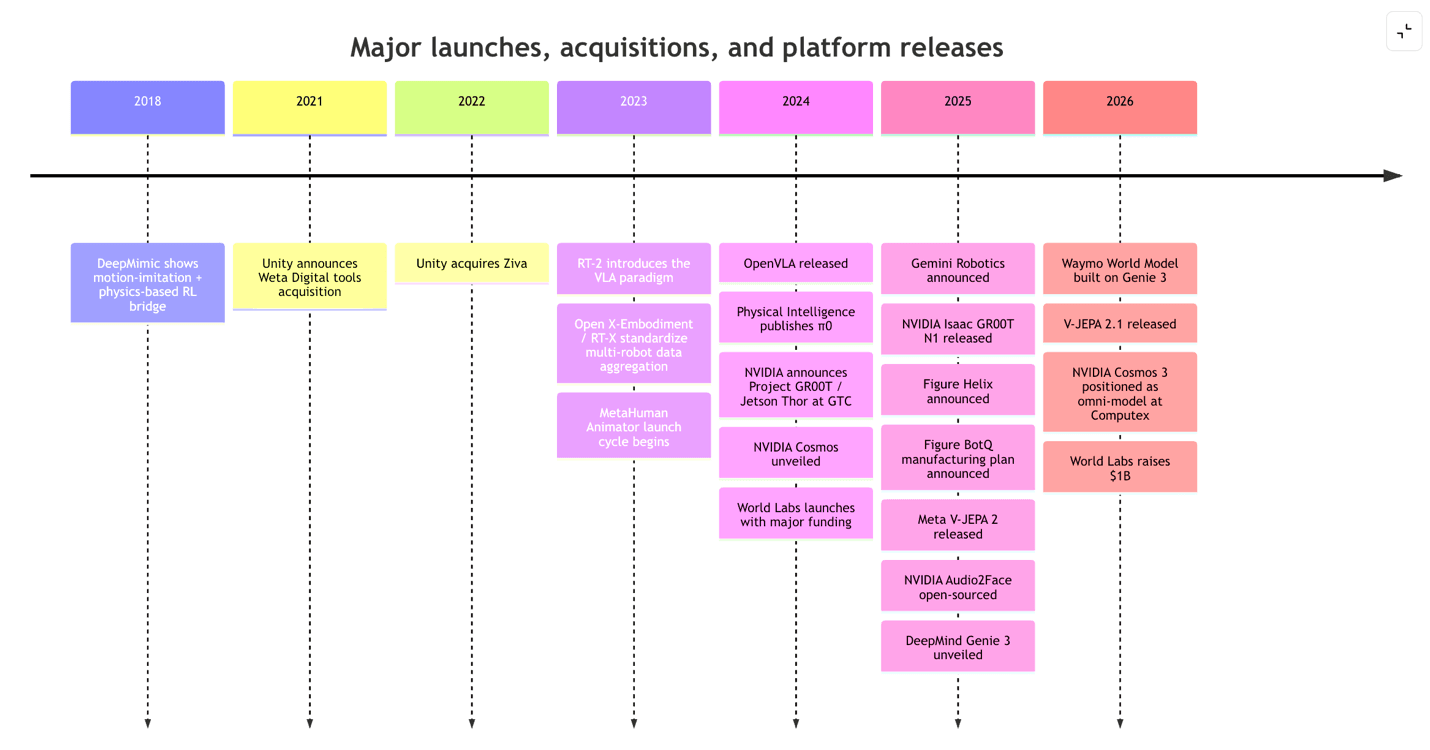
Platform Map and Timeline
Where Will Value Accrue?
Product lens. The short-term winners are unlikely to be companies selling “general robots” as a monolithic promise. The more credible near-term product categories are already visible: AI digital humans for training, onboarding, customer service, and brand interfaces; character-animation and facial-animation tools; synthetic actors and creator pipelines; simulation environments for robotics; teleop and demonstration tools; and VLA training-data pipelines. Those categories already have users, price points, and deployment surfaces. They also create flywheels that matter later for robotics because they accumulate 3D assets, motion priors, interaction data, and workflow lock-in.
Adoption lens. This is happening now because several constraints broke at once, as the previous section laid out: LLMs and VLMs solving enough of perception and language to make agent interfaces useful before dexterous control is solved, real-time engines and AI animation tools collapsing the cost of synthetic environments, real-world trial-and-error staying too expensive and too slow to substitute for simulation, and Hollywood-grade data finally meeting algorithms able to exploit it.
Monetization lens. The best way to phrase the thesis is this: the value is not in a single AI avatar, and not in a single humanoid demo. The value is in owning the infrastructure that turns motion into repeatable action-learning loops. That means motion-data systems, avatar and rigging systems, simulation substrates, world-model backbones, synthetic-data pipelines, evaluation loops, and deployment runtimes. NVIDIA is the clearest incumbent on this axis. Epic is highly relevant on the digital-human and authoring side. Figure is showing how full-stack ownership can become operationally defensible. World Labs, Meta, Google DeepMind, and Physical Intelligence are all plausible suppliers of future cognitive and world-model layers, but their ability to capture platform value depends on whether they own usage surfaces and training loops, not just headline models.
My strongest founder takeaway is that there is still a meaningful opportunity to build middleware with leverage: tools that normalize demonstrations into reusable action representations; systems that convert scans, CAD, or video into simulation-ready USD assets; evaluation layers for embodied models; teleop stacks that generate cleaner data; facial and body retargeting tools that bridge engine assets and robot-control datasets; and software that makes synthetic data trustworthy instead of merely abundant. Those businesses do not look as flashy as a humanoid reveal, but they are much closer to the bottlenecks.
My strongest investor takeaway is that “owns the simulation layer” is a better question than “who has the coolest robot.” The companies that own the reusable world representation, the data pipes, the evaluation harnesses, and the cost-efficient path from synthetic behavior to physical deployment are in the best position to capture cross-category value. In previous platform shifts, the durable winners usually sat one layer beneath the most visible demo. Embodied AI increasingly looks like another case of that pattern.
Hollywood's Greatest Special Effect
Avatar's motion-capture stage was never built to teach a machine anything. It was built so that an actor's grief, or anger, or joy, could survive the trip from a soundstage in Los Angeles to a blue nine-foot alien on a screen in front of a paying audience, without anything getting lost along the way.
That requirement — that nothing about how a human moves should be lost in translation — turned out to be the same requirement a robot needs to learn from a demonstration, or a world model needs to learn from a video, or a policy needs to learn from teleoperation. Hollywood was not trying to solve embodied AI. It was trying to solve fidelity. But fidelity to human motion and machine-readable representation of human motion are, it turns out, the same problem wearing different costumes.
The entertainment industry never set out to build the infrastructure of embodied intelligence. It was simply trying to make a smile arrive on time. In doing so, it may have built one of the foundations the entire field now stands on.
Sources
- Introduction to USD — Universal Scene Description documentation
- Isaac Sim — Robotics Simulation and Synthetic Data Generation, NVIDIA Developer
- C3D.ORG — The biomechanics standard file format
- Weta FX, Wikipedia
- Universal Scene Description: Schemas In-Depth
- MetaHuman — Digital Humans, Unreal Engine
- MetaHuman License
- V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning (arXiv)
- Physical AI with World Foundation Models, NVIDIA Cosmos
- RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control (arXiv)
- Open X-Embodiment: Robotic Learning Datasets and RT-X Models (arXiv)
- Helix: A Vision-Language-Action Model for Generalist Humanoid Control, Figure AI
- BotQ: A High-Volume Manufacturing Facility for Humanoid Robots, Figure AI
- p5.48xlarge pricing and specs, Vantage
- Everything Nvidia announced at its annual developer conference GTC, Reuters
- Nvidia is letting anyone use its AI voice animation tech, The Verge
- Synthesia Pricing
- Google says its new 'world model' could train AI robots in virtual warehouses, The Guardian
- pi-zero: A Vision-Language-Action Flow Model for General Robot Control (arXiv)
- Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success (arXiv)
- GR00T N1: An Open Foundation Model for Generalist Humanoid Robots (arXiv)
- Google introduces new AI models for rapidly growing robotics industry, Reuters
- Tesla to have humanoid robots for internal use next year, Musk says, Reuters
- AI pioneer Fei-Fei Li's World Labs raises $1 billion in funding, Reuters
- DeepMimic: Example-Guided Deep Reinforcement Learning of Physics-Based Character Skills (arXiv)